-
빅데이터 머신러닝 분석-코스피 코스닥 예측(1)빅데이터 2021. 10. 4. 00:07
예전부터 거시경제 지표를 활용하여 현재 코스피, 코스닥 지수를 평가해보고 싶었다. 개인적인 투자스타일은 지수초종보다는 개별종목단에서 투자하는 것을 선호하지만, 현재 전체 시장의 위치나 방향성을 알고 있다면 더 합리적인 의사결정을 할 수 있을것으로 생각한다.
Intro
먼저 가지고 있는 퀀트데이터 구성을 살펴보자.
18년 10월부터 21년 9월까지 3년치 월별 아래 데이터를 활용할 예정이다.(총 80개 칼럼)
코스피지수, 코스닥지수, 코스피시가총액, 코스닥시가총액, 유가, 환율, 경기선행지수, 월간수출액, 월간수입액, 월간순수출, 연환산수출액, 연환산무역규모, 연환산순수출, 코스피시총/연환산무역규모, 코스피연환산순익, 코스닥연환산순익, 코스피1년후PER, 코스피PER, 코스피PBR, 코스닥1년후PER, 코스닥PER, 코스닥PBR, 국채3년물, 수정일드갭, 고객예탁금, CMA잔고, 국내주식형펀드, 해외주식형펀드, 코스피신용, 코스닥신용, 코스피신용비율, 코스닥신용비율, 본원통화, M1, M2, LF, 다우지수, 상해종합주가, 니케이지수, 한국10년국채, 미국10년국채, 일본10년국채, 한국정책금리, 미국정책금리, 중국정책금리, 미국채3개월, 리보금리3개월, 회사채3개월AA, CRB선물, 금선물, 원엔환율, 미달러지수, 전년비경기선행지수, 전월비경기선행지수, TED스프레드, 외국금리스프레드, M2M1평균, 소비자물가상승률, 생산자물가상승률, 실질금리, 기업채산성, 코스피1년후순익, 코스닥1년후순익, 한국국채1년물, 미국국채1년물, 한국장단기금리차, 미국장단기금리차, 회사채3년BBB-, 구리선물, 납선물, 니켈선물, 옥수수선물, 대두선물, 설탕선물, 코스피코스닥신용합산
EDA
기본 라이브러리를 임포트한다.
중간에 잘리는 것을 방지하는 설정과 경고 메세지를 띄우지 않는 코드도 추가한다.
# 라이브러리 임포트 import pandas as pd import numpy as np import os from platform import python_version print(python_version()) print(pd.__version__) pd.set_option('display.max_row', 500) pd.set_option('display.max_columns', 100) import warnings warnings.filterwarnings(action='ignore')엑셀로 저장한 매크로 데이터를 임포트한다.
file_path = './data/macro_20210916.xlsx' df = pd.read_excel(file_path) df = df.set_index("시점") df = df.sort_index(ascending=True)먼저 코스피 코스닥 차트를 그려보자.(몇번을 돌아봐도 20년 3월은 끔찍하다.)
# 데이터 시각화 라이브러리 임포트 %matplotlib inline import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns sns.set_theme(style="white") mpl.rc('font', family='Malgun Gothic') mpl.__version__# 프로그램별 데이터 시각화 (라인 플롯) plt.figure(figsize=(10,10)) plt.plot(df["코스피지수"]) plt.xlabel('시점') plt.ylabel('지수') plt.title('코스피지수') plt.xticks(rotation=45) plt.show
# 프로그램별 데이터 시각화 (라인 플롯) plt.figure(figsize=(10,10)) plt.plot(df["코스닥지수"]) plt.xlabel('시점') plt.ylabel('지수') plt.title('코스닥지수') plt.xticks(rotation=45) plt.show
칼럼별 상관계수를 Heatmap으로 살펴보자. 칼럼의 수가 많으므로 내림차순으로 20개만 살펴보자.
Heatmap은 변수별 상관관계를 한눈에 확인할 수 있어서 EDA 때 도움이 많이 되는 것 같다.
corrmat = df.corr() plt.figure(figsize=(10,10)) k = 20 cols = corrmat.nlargest(k, '코스피지수')['코스피지수'].index cm = np.corrcoef(df[cols].values.T) hm = sns.heatmap(cm, cmap='Blues', cbar=True, annot=True, square=True, fmt='.2f', linewidths=0.01, annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values) plt.show()
plt.figure(figsize=(10,10)) k = 20 cols = corrmat.nlargest(k, '코스닥지수')['코스닥지수'].index cm = np.corrcoef(df[cols].values.T) hm = sns.heatmap(cm, cmap='Reds', cbar=True, annot=True, square=True, fmt='.2f', linewidths=0.01, annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values) plt.show()
머신러닝 분석에 필요한 라이브러리를 한번에 임포트하는 편이다.
# Essentials import datetime import random # Models from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor from sklearn.ensemble import AdaBoostRegressor, BaggingRegressor from sklearn.kernel_ridge import KernelRidge from sklearn.linear_model import Ridge, RidgeCV from sklearn.linear_model import ElasticNet, ElasticNetCV from sklearn.svm import SVR from mlxtend.regressor import StackingCVRegressor import lightgbm as lgb from lightgbm import LGBMRegressor from xgboost import XGBRegressor from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier from xgboost import XGBClassifier # Stats from scipy.stats import skew, norm from scipy.special import boxcox1p from scipy.stats import boxcox_normmax # Misc from sklearn.model_selection import GridSearchCV from sklearn.model_selection import KFold, cross_val_score from sklearn.metrics import mean_squared_error from sklearn.preprocessing import OneHotEncoder from sklearn.preprocessing import LabelEncoder from sklearn.pipeline import make_pipeline from sklearn.preprocessing import scale from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import RobustScaler from sklearn.decomposition import PCA from sklearn.preprocessing import MinMaxScalerX는 코스피/코스닥 지수로부터 파생된 칼럼들을 지우고 설정하고, Y는 코스피지수로 설정한다.
테스트 사이즈를 0.2로 설정했기 때문에 트레인 데이터는 28개, 테스트 데이터는 8개로 사이즈가 정해졌다.
x = df.drop(['코스피지수','코스닥지수', '코스피시가총액(조)', '코스닥시가총액(조)', '코스피시총/연환산무역규모', '코스피PER', '코스피PBR', '코스닥PER', '코스닥PBR'], axis=1) y = df['코스피지수'] x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 1) print(len(y_train)) print(len(y_test))스케일러는 가장 기본적인 MinMax 스케일러를 적용하였다.
# 스케일러 : MinMaxScaler, StandardScaler, RobustScaler scaler = MinMaxScaler() scaler.fit(x_train) scaler.fit(x_test) x_train = scaler.transform(x_train) x_test = scaler.transform(x_test)기본적인 트리기반 머신러닝 모델은 랜덤포레스트로 간단하게 예측정합성을 살펴보자.
rf = RandomForestClassifier(random_state = 1) rf.fit(x_train, y_train) pred = rf.predict(x_test) result = y_test.to_frame() result['예측'] = pred result = result.sort_index(ascending=True) result
result.plot(kind='bar', title="test data 예측결과", rot=45) plt.show()
단순 랜덤포레스트로는 20년 12월의 과소예측, 21년 9월의 과대예측의 문제가 있음을 대충 파악할 수 있다.
Setup cross validation and define error metrics
k-fold검증 및 손실함수를 정의하자.
kf = KFold(n_splits=10, random_state=1, shuffle=True) def rmsle(y_test, y_pred): return np.sqrt(mean_squared_error(y_test, y_pred)) def cv_rmse(model, x_train=x_train): rmse = np.sqrt(-cross_val_score(model, x_train, y_train, scoring="neg_mean_squared_error", cv=kf)) return (rmse)
Setup models
머신러닝 기법을 활용하여 학습모델을 설정하자.
# Light Gradient Boosting Regressor lightgbm = LGBMRegressor(objective='regression', num_leaves=6, learning_rate=0.01, n_estimators=7000, max_bin=200, bagging_fraction=0.8, bagging_freq=4, bagging_seed=8, feature_fraction=0.2, feature_fraction_seed=8, min_sum_hessian_in_leaf = 11, verbose=-1, random_state=42) # XGBoost Regressor xgboost = XGBRegressor(learning_rate=0.01, n_estimators=6000, max_depth=4, min_child_weight=0, gamma=0.6, subsample=0.7, colsample_bytree=0.7, objective='reg:linear', nthread=-1, scale_pos_weight=1, seed=27, reg_alpha=0.00006, random_state=42) # Ridge Regressor ridge_alphas = [1e-15, 1e-10, 1e-8, 9e-4, 7e-4, 5e-4, 3e-4, 1e-4, 1e-3, 5e-2, 1e-2, 0.1, 0.3, 1, 3, 5, 10, 15, 18, 20, 30, 50, 75, 100] ridge = make_pipeline(RobustScaler(), RidgeCV(alphas=ridge_alphas, cv=kf)) # Support Vector Regressor svr = make_pipeline(RobustScaler(), SVR(C= 20, epsilon= 0.008, gamma=0.0003)) # Gradient Boosting Regressor gbr = GradientBoostingRegressor(n_estimators=6000, learning_rate=0.01, max_depth=4, max_features='sqrt', min_samples_leaf=15, min_samples_split=10, loss='huber', random_state=42) # Random Forest Regressor rf = RandomForestRegressor(n_estimators=1200, max_depth=15, min_samples_split=5, min_samples_leaf=5, max_features=None, oob_score=True, random_state=42) # Stack up all the models above, optimized using xgboost stack_gen = StackingCVRegressor(regressors=(xgboost, lightgbm, svr, ridge, gbr, rf), meta_regressor=xgboost, use_features_in_secondary=True)scores = {} score = cv_rmse(lightgbm) print("lightgbm: {:.4f} ({:.4f})".format(score.mean(), score.std())) scores['lgb'] = (score.mean(), score.std()) score = cv_rmse(xgboost) print("xgboost: {:.4f} ({:.4f})".format(score.mean(), score.std())) scores['xgb'] = (score.mean(), score.std()) score = cv_rmse(svr) print("SVR: {:.4f} ({:.4f})".format(score.mean(), score.std())) scores['svr'] = (score.mean(), score.std()) score = cv_rmse(ridge) print("ridge: {:.4f} ({:.4f})".format(score.mean(), score.std())) scores['ridge'] = (score.mean(), score.std()) score = cv_rmse(rf) print("rf: {:.4f} ({:.4f})".format(score.mean(), score.std())) scores['rf'] = (score.mean(), score.std()) score = cv_rmse(gbr) print("gbr: {:.4f} ({:.4f})".format(score.mean(), score.std())) scores['gbr'] = (score.mean(), score.std())lgb_model_full_data = lightgbm.fit(x_train, y_train) xgb_model_full_data = xgboost.fit(x_train, y_train) svr_model_full_data = svr.fit(x_train, y_train) ridge_model_full_data = ridge.fit(x_train, y_train) rf_model_full_data = rf.fit(x_train, y_train) gbr_model_full_data = gbr.fit(x_train, y_train)각 모델을 조합한 하이브리드 모델도 설정해보자.
def hybrid_predictions(X): return ((0.1 * ridge_model_full_data.predict(X)) + \ (0.2 * svr_model_full_data.predict(X)) + \ (0.1 * gbr_model_full_data.predict(X)) + \ (0.1 * xgb_model_full_data.predict(X)) + \ (0.1 * lgb_model_full_data.predict(X)) + \ (0.05 * rf_model_full_data.predict(X)) + \ (0.35 * stack_gen_model.predict(np.array(X)))) hybrid_score = rmsle(y_train, hybrid_predictions(x_train)) scores['hybrid'] = (hybrid_score, 0) print('RMSLE score on train data:') print(hybrid_score)각 모델의 RMSE 값을 비교해보자.
fig = plt.figure(figsize=(24, 12)) ax = sns.pointplot(x=list(scores.keys()), y=[score for score, _ in scores.values()], markers=['o'], linestyles=['-']) for i, score in enumerate(scores.values()): ax.text(i, score[0] + 0.002, '{:.6f}'.format(score[0]), horizontalalignment='left', size='large', color='black', weight='semibold') plt.ylabel('Score (RMSE)', size=20, labelpad=12.5) plt.xlabel('Model', size=20, labelpad=12.5) plt.tick_params(axis='x', labelsize=13.5) plt.tick_params(axis='y', labelsize=12.5) plt.title('Scores of Models', size=20) plt.show()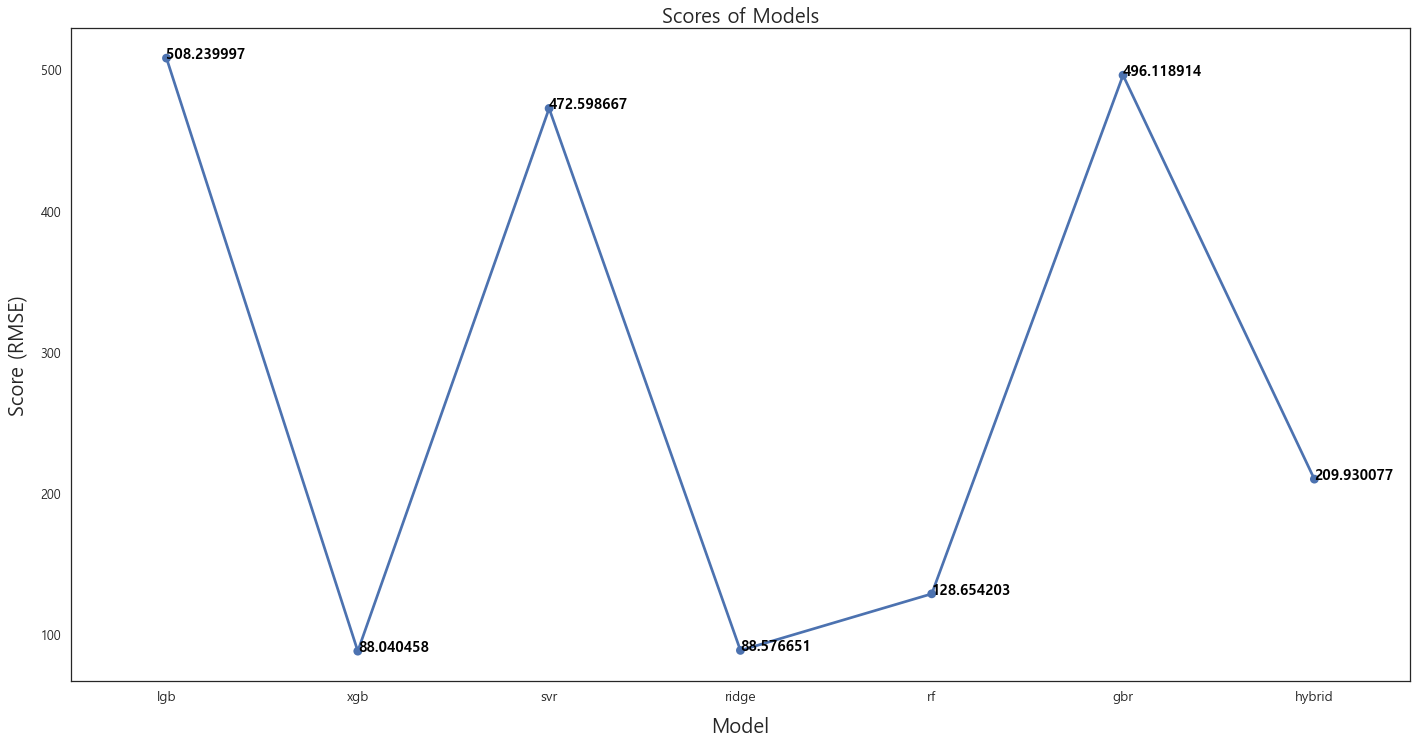
하이브리드 모델이 가장 낮은 RMSE값을 가질 것으로 예상했으나, 데이터의 양이 36개 set 밖에 없어서 그런지 XGBoost 모델이 가장 낮은 RMSE값을 가졌다. 일단 최초 랜덤포레스트 모델과 비교를 위하여 하이브리드 모델로 예측값을 나타내보자.
result = y_test.to_frame() result['예측'] = hybrid_predictions(x_test) result = result.sort_index(ascending=True) result
result.plot(kind='bar', title="test data 예측결과", rot=45) plt.show()
최초 랜덤포레스트 모델과 하이브리드 모델을 비교해보자.


자세히 쳐다봐도 큰 차이는 없는 것 같다. (코스닥도 마찬가지)
Result
1. 장기간의 데이터로 머신러닝 모델학습 필요하다. 36개 데이터 셋으로는 턱없이 부족하다.
2. 다중공선성 문제 해결을 위한 요인분석 필요하다. 80개의 칼럼이 있지만 요인별 상관관계가 높은 칼럼들을 묶어서 분석하는 스킬을 배워야 될 것 같다.
3. 천재적인 데이터 사이언티스트들도 아직 주식시장을 정복하지 못했다. 큰 기대는 하지말고 배운 것을 계속 활용한다는 측면에서 접근하자.
4. 구리선물은 왜 코스피/코스닥 지수와 상관관계가 높은걸까?
'빅데이터' 카테고리의 다른 글
효율적 투자선(Efficient Frontier) 포트폴리오 최적화(feat.파이썬)(2) (0) 2021.10.10 효율적 투자선(Efficient Frontier) 포트폴리오 최적화(feat.파이썬)(1) (0) 2021.10.10